КріптоПро
У цій замітці будуть розглянуті особливості алгоритму ГОСТ 28147-89 з точки зору побудови його ефективних реалізацій. Ми обговоримо кілька актуальних напрямків в області оптимізації продуктивності ПО і покажемо, що алгоритм ГОСТ 28147-89 має низку вельми приємних для їх застосування особливостей.
В останні роки акцент в області оптимізації продуктивності програмного забезпечення змістився в бік активного використання паралельних обчислень. Це пов'язано зі зниженням темпу зростання тактової частоти CPU: якщо раніше швидкість програми збільшувалася незалежно від розробника через постійне зростання обчислювальної потужності CPU, прискорення обміну даними з пам'яттю і периферією, то зараз відповідальність за збільшення швидкості виконання програм лягає в більшій мірі на програмістів. Тепер для досягнення максимальної продуктивності додатка програмісти повинні враховувати можливості паралелізму, доступні в цільовій системі. До таких можливостей відносяться:
- розпаралелювання задачі між ядрами процесора;
- використання векторних розширень CPU;
- використання GPU.
Алгоритм ГОСТ 28147-89 виявляється вельми зручним з точки зору підвищення ефективності його реалізації за допомогою описаних вище можливостей. Нас будуть цікавити, звичайно ж, ті способи підвищення ефективності реалізацій, які за своєю суттю спираються на властивості самого алгоритму шифрування. Ми розглянемо також питання про побудову легковажних реалізацій, так як для них при вирішенні задач оптимізації ГОСТ 28147-89 корисним виявляється той же набір властивостей алгоритму, що і при використанні GPU і векторних розширень CPU.
ГОСТ 28147-89 і векторні розширення CPU
Говорячи про паралельних обчисленнях на одному комп'ютері, найчастіше мають на увазі одночасні обчислення на декількох процесорах (або ядрах одного процесора). Але крім цього існує також можливість паралельних обчислень в межах одного ядра - це використання векторних інструкцій.
Векторні інструкції дозволяють виробляти кілька операцій за один такт процесора, наприклад, складати відразу кілька чисел.
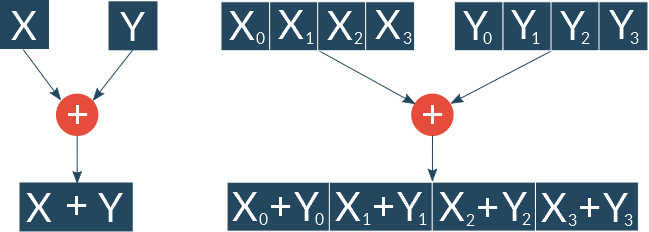
Можливість виконання векторних операцій в сучасних обчислювальних системах на платформах x86 / x64 забезпечується спеціальними процесорними розширеннями SSE і AVX. Ці розширення додають нові регістри довжиною 128 і більше біт, а також інструкції для роботи з ними.
Покажемо, як можна застосувати ці розширення для ефективної реалізації алгоритму ГОСТ 28147-89 (опис деяких ідей використання даних розширень можна знайти також в статті [ 5 ]).
Як відомо, один раунд алгоритму ГОСТ 28147-89 складається з складання з ключем по модулю 2, восьми 4-х бітових вузлів заміни і циклічного зсуву на 11 біт вліво. Очевидно, що виграш в продуктивності за рахунок використання векторних інструкцій можна отримати, тільки обробляючи кілька блоків за раз. Причому чим більша кількість блоків буде обраховуватися одночасно, тим більший виграш в швидкості ми отримаємо. Розмір блоку в алгоритмі ГОСТ 28147-89 дорівнює 64 бітам, але так як використовується мережу Фейстеля, все ресурсомісткі перетворення проводяться тільки над половиною блоку, тобто над 32 бітами даних. Ця особливість алгоритму дозволяє нам, наприклад, складати з раундовим ключем або циклічно зрушувати одночасно кілька блоків, використовуючи один AVX-регістр.
На окрему увагу заслуговують вузли замін. Справа в тому, що в розширенні AVX була додана команда VPSHUFB , Яка копіює байти з регістра-джерела в регістр-приймач в порядку, описаному в індексному регістрі.
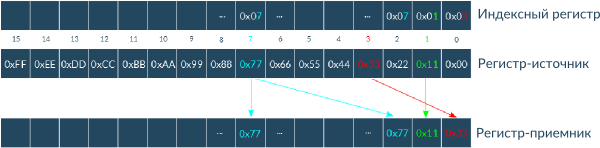
Якщо в регістр-джерело записати таблицю замін, а в індексний регістр (в молодші напівбайтів) помістити оброблювані дані, то за допомогою цієї інструкції можна за один такт процесора зробити заміну для 16 напівбайт, що дозволяє отримати значний виграш в швидкості в порівнянні з послідовним застосуванням вузлів замін.
Варто зазначити, що ефективне використання цієї інструкції можливо тільки завдяки тому, що в алгоритмі ГОСТ 28147-89 використовуються саме 4-бітові вузли замін. Дійсно, так як команда VPSHUFB використовує тільки молодші 4 біти кожного байта індексного регістра, то і замінювати ми можемо відповідно тільки їх. До того ж одна таблиця замін для 4 біт має розмір 24 · 4 = 64 біта, що дозволяє в один 128-бітний регістр помістити відразу дві таблиці.
Тепер перейдемо безпосередньо до цифр. На графіках нижче представлені результати вимірювань швидкості шифрування в режимі гамування (режиму, який досить часто використовується в криптографічних протоколах) в залежності від числа потоків. Виміри проводилися на стендах №1 , №2 і №3 . Стенд №1 імітує серверний комп'ютер, стенди №2 і №3 - звичайні комп'ютери користувачів.
При реалізації протоколів TLS і IPsec для контролю цілісності даних використовується имитовставка за алгоритмом ГОСТ 28147-89, тому поширеною завданням при використанні цих протоколів є шифрування з одночасним обчисленням имитовставки. Нижче представлений графік залежності швидкості шифрування з одночасним обчисленням имитовставки від кількості потоків. На графіку режим MultiPacket позначає одночасну обробку декількох пакетів, докладніше цей режим описаний в документації на КріптоПро CSP .
ГОСТ і GPU
Розглядаючи ефективні реалізації криптографічних алгоритмів, не можна не згадати про такий напрямок як GPGPU (General-purpose graphics processing units).
GPGPU - це техніка використання графічних процесорів в обчисленнях загального характеру, тобто не пов'язаних з обробкою графіки - наприклад, в криптографії.
Розглянемо, в чому ж полягають переваги використання GPU для обчислень загального характеру.
По-перше, це кількість ядер. Якщо центральні процесори мають в середньому від 2 до 16 ядер, то графічні - від декількох сотень до декількох тисяч - наприклад, графічний процесор GeForce GTX 970 містить 1664 ядра, а Radeon R9 295X2 - 5632.
По-друге, це призначення транзисторів. У центральному процесорі велика частина транзисторів використовується для кеша і управління потоком виконання, в той час як в графічних процесорах велика частина транзисторів використовується для обчислень.
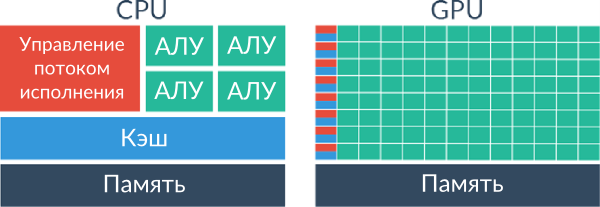
По-третє, це пропускна здатність пам'яті, яка у графічних процесорів в кілька разів більше. Для прикладу, при використанні процесора Intel Xeon E5-2670 та 4-х модулів оперативної пам'яті DDR3 пропускна здатність пам'яті становить приблизно 80 Гб / с, в той час як пропускна здатність пам'яті вже згадуваних графічних процесорів GeForce GTX 970 і Radeon R9 295X2 становить 224 і 680 Гб / с відповідно.
Щоб пояснити, що ж хороший алгоритм ГОСТ 28147-89 для реалізації на GPU, потрібно спочатку трохи розповісти про принцип обчислень на GPU.
Не вдаючись в подробиці, будь-яка програма на GPU містить кілька основних кроків, зображених на малюнку нижче.

Дані на етапі обчислень на GPU обробляються в кілька тисяч потоків. Потоки виконуються в повному обсязі одночасно, а групами. Під час роботи однієї такої групи все ресурси графічного процесора (векторні і скалярні регістри, пам'ять і т.п.) діляться між потоками цієї групи, тому кількість потоків в групі залежить від ресурсів використовуваних одним потоком для обчислень. Очевидно, що чим менше ресурсів використовує один потік, тим більше потоків може виконуватися на GPU одночасно, а, отже, тим вище буде швидкість роботи програми.
Тому для досягнення високої швидкості роботи будь-якого алгоритму на GPU необхідно мінімізувати кількість ресурсів, використовуваних їм для обчислень.
З цієї точки зору алгоритм ГОСТ 28147-89 має ряд переваг. По-перше, це проста процедура отримання раундовий ключів, яка не вимагає багато ресурсів. По-друге, за допомогою перевирахованой таблиці можна спростити раундовому перетворення. Таким чином, замість восьми 4-бітових вузлів замін і циклічного зсуву ми маємо складання по модулю 2 чотирьох елементів з перевирахованой таблиці. Все це значно знижує кількість апаратних ресурсів, необхідних для роботи алгоритму, і істотно збільшує швидкість його роботи на GPU.
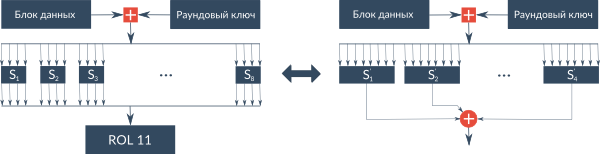
Інший спосіб оптимізації базового циклу алгоритму ГОСТ 28147-89 для GPU був запропонований в роботі [ 4 ]. Для зменшення кількості звернень до пам'яті автор пропонує реалізувати таблицю заміни через булеву функцію, що значно підвищує швидкість роботи алгоритму.
На графіку нижче представлені результати швидкості шифрування на GPU для різних алгоритмів для побудованої на основі даних ідей реалізації. Всі вимірювання зроблені на тестовому стенді №2 . Під час тестів в режимі простої заміни шифрувалися дані розміру 256 МБ і вимірювалася теоретична і практична продуктивність реалізації алгоритму. Теоретична продуктивність показує швидкість безпосередньо шифрування на GPU, а практична - з корость шифрування + копіювання даних в пам'ять GPU і результатів з пам'яті GPU в оперативну. Реалізації алгоритмів для OpenCL (крім реалізації ГОСТ 28147-89) взяті з відкритого проекту engine-cuda .
Як видно з графіка, практична швидкість шифрування на GPU слабо корелює з теоретичної. Відбувається це через те, що більшу частину часу в реальних умовах займають операції копіювання даних з оперативної пам'яті в пам'ять GPU і назад. Все це ускладнює використання GPU для шифрування на практиці.
ГОСТ і легка криптографія
Останнім часом активно розвивається такий напрямок, як легка (lightweight) криптографія. Основне завдання цього напряму - це проектування і реалізація криптографічних алгоритмів для пристроїв з невеликою обчислювальною потужністю, таких як смарт-карти, сенсори, RFID-мітки. Реалізації бувають апаратні - це інтегральні схеми (ASIC), і програмні - це код для програмованих мікроконтролерів.
Основні цілі легковагій криптографії - це мінімізація ресурсів, необхідних для реалізації алгоритму, при збереженні його стійкості і швидкості роботи. Під ресурсами маються на увазі розмір пристрою, споживана їм потужність і його вартість (в разі програмної реалізації це будуть параметри використовуваного мікроконтролера). При таких умовах в більшості випадків апаратні реалізації за всіма параметрами перевершують програмні, тому зупинимося саме на них.
Проектування легковагій апаратної реалізації здебільшого полягає в знаходженні оптимального балансу між усіма параметрами такої схеми.
Параметри апаратної реалізації, тобто інтегральної схеми, багато в чому визначаються площею, займаної схемою на кристалі кремнію. Чим менше площа - тим менше розміри і вартість. Але ця величина сильно залежить від технологій, які використовуються виробником. Тому в якості основної характеристики апаратної реалізації в легковагій криптографії використовується gate equivalents (GE). Ця характеристика показує, скільки елементів NAND ( "І-НЕ") можна розмістити на площі, займаної заданої схемою. Отже, чим менше кількість GE, тим менше площа схеми, а значить краще її параметри.
Тепер перейдемо безпосередньо до апаратної легковагій реалізації алгоритму ГОСТ 28147-89. Визначальним властивістю алгоритму в даному випадку є проста процедура отримання раундовий ключів. Це властивість дозволяє досягти хороших показників апаратної реалізації. В роботі [ 1 ] При використанні 8 однакових вузлів заміни з шифру PRESENT [ 2 ] Досягається 650 GE і 800 GE при використанні таблиці заміни TestParamSet.
Таким чином, для легковагій реалізації ГОСТ 28147-89 корисним виявляється той же набір властивостей алгоритму, що і при використанні GPU і векторних розширень CPU. І цей набір властивостей допомагає домогтися гарних параметрів апаратної реалізації алгоритму таких, як маленький розмір, мала споживана потужність і низька вартість. Все це дозволяє ефективно використовувати ГОСТ 28147-89 в смарт-картах, сенсорах, RFID-мітки.
Підведемо підсумки
З точки зору створення ефективних реалізацій алгоритм ГОСТ 28147-89 має цілу низку переваг. По-перше, це просте ключове розклад. По-друге, це використання 4-бітових вузлів заміни, які в програмних реалізаціях добре здійснюються за допомогою векторних інструкцій, а в апаратних вимагають вкрай мало ресурсів. І по-третє, це просте раундовому перетворення в цілому, яке добре лягає як на програмні, так і на апаратні реалізації. При цьому алгоритм досі володіє колосальним з точки зору практики запасом міцності, про що ми писали в нашій попередній статті . А за допомогою невеликої модифікації ключового розкладу, запропонованої в роботі [ 3 , 6 ], Можна виключити можливість здійснення навіть теоретичних атак (методи Ісобе і Дінур-Данкельмана-Шаміра).
Додаток: Зміни тестових стендів
Конфігурація тестового стенда №1
Материнська плата Supermicro, X9DR3-F, Версія BIOS American Megatrends Inc. 1.1, 03.10.2012 Процесор 2 ЦП Xeon (R) E5-2680 2.7 ГГц, Hyper-Threading включений, всього 32 логічних процесора (сімейство Sandy Bridge) ОЗУ 32 Гб Жорсткий диск 256 Gb SSD ОС Windows Server 2008 R2 Версія КріптоПро CSP 3.6 R3
Конфігурація тестового стенда №2
Материнська плата Asus M5A99X Evo, версія BIOS American Megatrends Inc. 01.06.2011 Процесор QuadCore AMD FX-4100, 4154 MHz Відеокарта AMD Radeon HD 6970 ОЗУ 2 x 4Gb DDR3 1333 MHz Жорсткий диск Non-SSD 1TB ОС Windows 7 x64 Версія КріптоПро CSP 4.0
Конфігурація тестового стенда №3
Комп'ютер MacBook Pro 17 "початок 2011 Процесор Core i7, 2.3 ГГц, Hyper-Threading включений, всього 8 логічних процесора (сімейство Sandy Bridge) ОЗУ 8 Гб Жорсткий диск 512 Гб SSD ОС Mac OS X Lion 10.7.5 Версія КріптоПро CSP 3.6 R3
література
[1] Poschmann, A., Ling, S., Wang, H .: 256 bit standardized crypto for 650 GE - GOSTrevisited. In: Mangard, S., Standaert, F.-X. (Eds.) CHES 2010. LNCS, vol. 6225, pp. 219-233. Springer, Heidelberg (2010)
[2] Bogdanov, A., Leander, G., Knudsen, L., Paar, C., Poschmann, A., Robshaw, M., Seurin, Y., Vikkelsoe, C .: PRESENT - An Ultra-Lightweight Block Cipher. In: Paillier, P., Verbauwhede, I. (eds.) CHES 2007. LNCS, vol. 4727, pp. 450-466.Springer, Heidelberg (2007)
[3] Дмух А.А., маршалком Г.Б. Про можливість модифікації алгоритму шифрування ГОСТ 28147-89 зі збереженням прийнятних експлуатаційних характеристик. Матеріали XV міжнародної конференції "РусКріпто'2013".
[4] Кролевецький А.В .: Ефективна реалізація алгоритму ГОСТ 28147-89 за допомогою технології GPGPU. Матеріали XVI міжнародної конференції "РусКріпто'2014".
[5] Досягаємо феноменальною швидкості на прикладі шифрування ГОСТ 28147-89. Журнал "Хакер". https://xakep.ru/2013/10/19/shifrovanie-gost-28147-89/
[6] AA Dmukh, DM Dygin, GB Marshalko, "A lightweight-friendly modification of GOST block cipher", Матем. пит. Криптограми. , 5: 2 (2014 року), 47-55
Смишляєв С.В., к.ф.-м.н.,
начальник відділу захисту інформації
ТОВ "крипто-ПРО"
Алексєєв Е.К., к.ф.-м.н.,
провідний інженер-аналітик
ТОВ "крипто-ПРО"
Прохоров А.С.,
інженер-аналітик 2 категорії
ТОВ "крипто-ПРО"
